Apple Health Export Part I
This post is Part I of a dive into the contents of the Apple Health Export. It will work through the mechanics of moving data from the Apple Health app out of your iPhone and into R where you can analyze it. It also will describe in detail the problem of adjusting the time stamps for daylight savings time and travel across time zones. Unfortunately the topic of time zones and the Apple Health Export is a complicated subject.
First, Export the Data from the Health App
You can export all of the data you are able to view via the Health app. Open the Health app on your iPhone. To export, go to your personal settings by clicking on your icon near the upper right corner of the Browse screen. (See the the first screenshot below.) Click on the icon and you will see some of your personal settings. You will need to scroll to the bottom of this page, where you will see a clickable line “Export All Health Data”, as shown in the second screenshot below.
Tap upper right icon:
Scroll to very bottom:
Once you click OK to go ahead with the export, it may take a significant amount of time. On my iPhone 8 it takes more than five minutes. Once it is complete, you’ll get a dialog that asks where to send the exported data. I use AirDrop to send it to the Mac where I am running RStudio. It ends up in the Downloads folder on that Mac. If you need to move the data to a Windows computer, you may need to send it via email or Dropbox. The exported file is named export.zip. If you double-click on that file it will expand into a folder called apple_health_export. The uncompressed file is huge in comparison with the size of the zip file. In my case, export.zip is about 79 megabytes which becomes an apple_health_export folder that is 2.45 gigabytes! In my R code, I uncompress the file into my Downloads folder, which is excluded from my Time Machine backups.
R Code to Expand the Export File and Import It As XML Data
The R code below shows how to decompress export.zip and follow some basic steps to import it into R. I’m following in the footsteps of several people who have published code to accomplish these steps. See work by Ryan Praskievicz, Taras Kaduk, and Deepankar Datta (who has created a package called AppleHealthAnalysis). I’m sure there are other examples using R, and there are quite a number of examples using python (e.g., by Mark Koester).
The R code uncompresses the zip file and replaces the apple_health_export folder. (Because of the size of this folder, I try to avoid having multiple copies and also avoid having it saved to my disk backup.) The big file inside that folder is export.xml. Following the examples cited above, I use the XML package to covert the major elements of the XML file into tidy data frames.
See a later post for some explanation of the problem and a tip that may help you to fix the export file so you can load it into R.
if (file_exists("~/Downloads/export.zip")) {
rc <- unzip("~/Downloads/export.zip", exdir = "~/Downloads", overwrite = TRUE)
if (length(rc) != 0) {
# once unzipped, delete export.zip. Otherwise, the next time Air Drop sends export.zip
# to your mac it will be renamed as export2.zip and you may accidentally process
# an out-of-date set of data.
# takes a bit more than 20 seconds on my iMac
health_xml <- xmlParse("~/Downloads/apple_health_export/export.xml")
# takes about 70 seconds on my iMac
health_df <- XML:::xmlAttrsToDataFrame(health_xml["//Record"], stringsAsFactors = FALSE) %>%
as_tibble() %>% mutate(value = as.numeric(value))
activity_df <- XML:::xmlAttrsToDataFrame(health_xml["//ActivitySummary"], stringsAsFactors = FALSE) %>%
as_tibble()
workout_df <- XML:::xmlAttrsToDataFrame(health_xml["//Workout"], stringsAsFactors = FALSE) %>%
as_tibble
clinical_df <- XML:::xmlAttrsToDataFrame(health_xml["//ClinicalRecord"]) %>%
as_tibble()
save(health_xml, health_df, activity_df, workout_df, clinical_df,
file = paste0(path_saved_export, "exported_dataframes.RData"))
if (file.exists("~/Downloads/export.zip")) file.remove("~/Downloads/export.zip")
}
} I won’t go into the details of the XML structure of the health export. For most purposes, the Record, ActivitySummary, Workout, and Clinical data types will provide all that you are looking for. My expanded Apple Health Export folder also includes workout GPX files, electrocardiograms, and clinical records imported from my health system’s medical records system.
I have a bit over two years of Apple Watch data in my iPhone. After a full career working as a data analyst, this is the largest number of data points I have ever dealt with. Extracting the “Record” data from export.xml produces more than four million rows and takes about 70 seconds on my 2019 iMac.
The Types of Data in the Export
The counts by “type” describe the breadth and quantity of data are shown in Table 1.
Table 1: ?(caption)
| type | Watch | Phone | Lose It! | Other | Total |
|---|---|---|---|---|---|
| HKQuantityTypeIdentifierActiveEnergyBurned | 1,120,202 | 0 | 0 | 2 | 1,120,204 |
| HKQuantityTypeIdentifierHeartRate | 502,394 | 0 | 0 | 2,642 | 505,036 |
| HKQuantityTypeIdentifierDistanceWalkingRunning | 259,806 | 157,767 | 0 | 2 | 417,575 |
| HKQuantityTypeIdentifierBasalEnergyBurned | 362,927 | 0 | 0 | 0 | 362,927 |
| HKQuantityTypeIdentifierStepCount | 81,132 | 158,903 | 0 | 2 | 240,037 |
| HKQuantityTypeIdentifierAppleExerciseTime | 85,863 | 453 | 0 | 0 | 86,316 |
| HKQuantityTypeIdentifierFlightsClimbed | 20,095 | 17,922 | 0 | 2 | 38,019 |
| HKQuantityTypeIdentifierAppleStandTime | 34,806 | 24 | 0 | 0 | 34,830 |
| HKCategoryTypeIdentifierAppleStandHour | 29,547 | 10 | 0 | 0 | 29,557 |
| HKQuantityTypeIdentifierEnvironmentalAudioExposure | 24,436 | 0 | 0 | 0 | 24,436 |
| HKQuantityTypeIdentifierDietaryFatTotal | 0 | 0 | 9,922 | 0 | 9,922 |
| HKQuantityTypeIdentifierDietaryEnergyConsumed | 0 | 0 | 9,524 | 0 | 9,524 |
| HKQuantityTypeIdentifierDietaryFatSaturated | 0 | 0 | 9,124 | 0 | 9,124 |
| HKQuantityTypeIdentifierDietaryFiber | 0 | 0 | 8,951 | 0 | 8,951 |
| HKQuantityTypeIdentifierDietaryProtein | 0 | 0 | 8,914 | 0 | 8,914 |
| HKQuantityTypeIdentifierDietarySodium | 0 | 0 | 8,903 | 0 | 8,903 |
| HKQuantityTypeIdentifierDietarySugar | 0 | 0 | 8,671 | 1 | 8,672 |
| HKQuantityTypeIdentifierDietaryCholesterol | 0 | 0 | 8,391 | 0 | 8,391 |
| HKQuantityTypeIdentifierHeartRateVariabilitySDNN | 7,878 | 0 | 0 | 0 | 7,878 |
| HKQuantityTypeIdentifierWalkingStepLength | 0 | 6,176 | 0 | 0 | 6,176 |
| HKQuantityTypeIdentifierWalkingSpeed | 0 | 6,161 | 0 | 0 | 6,161 |
| HKCategoryTypeIdentifierSleepAnalysis | 1,166 | 306 | 0 | 4,504 | 5,976 |
| HKQuantityTypeIdentifierWalkingDoubleSupportPercentage | 0 | 5,160 | 0 | 0 | 5,160 |
| HKQuantityTypeIdentifierBloodPressureDiastolic | 0 | 0 | 0 | 4,344 | 4,344 |
| HKQuantityTypeIdentifierBloodPressureSystolic | 0 | 0 | 0 | 4,344 | 4,344 |
| HKQuantityTypeIdentifierStairDescentSpeed | 3,288 | 0 | 0 | 0 | 3,288 |
| HKQuantityTypeIdentifierStairAscentSpeed | 3,236 | 0 | 0 | 0 | 3,236 |
| HKQuantityTypeIdentifierOxygenSaturation | 2,905 | 0 | 0 | 57 | 2,962 |
| HKQuantityTypeIdentifierWalkingAsymmetryPercentage | 0 | 1,462 | 0 | 0 | 1,462 |
| HKQuantityTypeIdentifierRestingHeartRate | 1,258 | 0 | 0 | 0 | 1,258 |
| HKQuantityTypeIdentifierWalkingHeartRateAverage | 1,178 | 0 | 0 | 0 | 1,178 |
| HKQuantityTypeIdentifierBodyMass | 0 | 1 | 564 | 92 | 657 |
| HKQuantityTypeIdentifierVO2Max | 488 | 0 | 0 | 0 | 488 |
| HKQuantityTypeIdentifierDistanceCycling | 458 | 0 | 0 | 0 | 458 |
| HKQuantityTypeIdentifierHeadphoneAudioExposure | 0 | 147 | 0 | 0 | 147 |
| HKCategoryTypeIdentifierMindfulSession | 145 | 0 | 0 | 0 | 145 |
| HKQuantityTypeIdentifierSixMinuteWalkTestDistance | 0 | 14 | 0 | 0 | 14 |
| HKCategoryTypeIdentifierAudioExposureEvent | 2 | 0 | 0 | 0 | 2 |
| HKQuantityTypeIdentifierHeight | 0 | 1 | 0 | 1 | 2 |
| HKQuantityTypeIdentifierNumberOfTimesFallen | 2 | 0 | 0 | 0 | 2 |
| HKCategoryTypeIdentifierDizziness | 0 | 0 | 0 | 1 | 1 |
| HKCategoryTypeIdentifierECGOtherSymptom | 0 | 0 | 0 | 1 | 1 |
| HKCategoryTypeIdentifierRapidPoundingOrFlutteringHeartbeat | 0 | 0 | 0 | 1 | 1 |
| HKDataTypeSleepDurationGoal | 0 | 0 | 0 | 1 | 1 |
| HKQuantityTypeIdentifierDietaryCaffeine | 0 | 0 | 0 | 1 | 1 |
| HKQuantityTypeIdentifierDietaryCarbohydrates | 0 | 0 | 0 | 1 | 1 |
| Total | 2,543,212 | 354,507 | 72,964 | 15,999 | 2,986,682 |
The same data may be repeated from multiple sources so it is important to pay attention to sourceName. Note that step counts, flights climbed, and distance walking/running are recorded from both the Watch and the iPhone. On any particular day you probably want to include only one of the sources. Otherwise you risk double counting. Generally I focus on the Watch data, but I have almost three years of data from my iPhone before I started wearing the Apple Watch.
The largest quantity of data is collected via my Apple Watch rather than my iPhone. There are other sources as well. I have been using the Lose It! app on my iPhone for about six months to count calories, and that produces a noticeable amount of data. The free version of the app that I am using does not display much beyond basic calorie counts. It’s interesting to see that the more detailed nutrition breakdowns are passed into the Health app.
As far as the “Other” category, I’m using an Omron blood pressure cuff that can transfer readings to the Omron app on the iPhone via Bluetooth. Those readings are then updated in the Apple Health database. There are a few odds and ends contributed by apps on my iPhone such as AllTrails, Breathe, and AutoSleep. Note that heart rate data comes both from the watch and from the blood pressure data.
The other major XML categories are ActivitySummary, Workout, and ClinicalRecord. For ActivitySummary I have one row per day which basically summarizes some of the intra-day activity data. Workout has one row per workout. If I were still running I would focus much more on that data frame. For each workout it shows type, distance, duration, and energy burned Most of my workouts are outdoor walks. Quite often I forget to end the workout when I end the walk, which certainly reduces the usefulness of the data. But I would imagine that for a runner or a swimmer or a cyclist, the Workout information would be interesting and useful.
ClinicalRecord is a bit tricky. I have set things up so that my health organization shares my health records with the Apple Health app.
In the clinical data frame there is a column called resourceFilePath that contains the path to a json dataset in the Apple Health Export/clinical records folder. Presumably this would allow you to retrieve items such as individual lab test results. I haven’t attempted to get into this data. I only know what’s available here because I can view it via the Apple Health app.
The Problem of Time Zones and of Daylight Savings
When I first looked at day by day data for resting heart rate I bumped into problems caused by the issue of time zones. I have about 800 rows of data of type HKQuantityTypeIdentifierRestingHeartRate which should be one per day. I quickly discovered I had several days where there were two values in a single day, and these were related to occasions when I traveled by air to a different time zone.
This leads to a long digression on the subject of computer time stamps and time zones. (Here is an entertaining video that describes the general problem of time stamps and time zones, but it doesn’t relate to the specific problems that I will get into here. It’s fun if you want to nerd out on this topic.)
Attention Conservation Notice: If you don’t care about time of day and can tolerate a few things like resting heart rate being a day off, then you can ignore the issues with the time stamps. Your life will be a lot simpler. You can basically skip the rest of this post and look forward to Part II.
Now we shall dive deep into the weeds. Each item in the records of the health dataset has a creation, start, and end time stamp. In the export dataset they appear as a character string that looks like this: “2019-04-10 08:10:34 -0500”. There is “-0500” on the end because as I write this local time is Eastern Standard Time which is five hours earlier than UTC (universal time code). At first I thought the time code offset at the end of the text string would take care of everything. In fact, it is useless. As near as I can tell, the internal data has no indication of time zone.1 The UTC offset is attached to the date and time information when the data is exported. Every single time stamp in the exported dataset has the same “-0500” offset, which merely represent my local offset at the time the export was done. When I exported the data during Eastern Daylight Savings, all of the offsets appeared as “-0400”. In fact, the exported data has no information about time zone or daylight savings. One should think of the actual time stamp as being in universal time (UTC). The export creates a character string which displays the date and time in the time zone where and when the export is created and attaches an offset to UTC.
Here is a detailed example. When I go into the Activity app on my iPhone I see that it claims I started a walk in England on 9/1/2019 at 05:51:58. I’m not that much of an early riser. I know from my travel diary that I actually got started five hours later than that at 10:51:58 local time (British Summer Time) because I had to take a bus before I could start the walk. When I exported the workout data last October during Daylight Savings, the exported date showed “2019-09-01 05:51:58 -0400”. When I export the data now during standard time it shows “2019-09-01 04:51:58 -0500”. If I feed either of those character strings into lubridate::as_datetime I get “2019-09-01 09:51:58 UTC”. In absolute terms, there’s no ambiguity about when the observation was added to the data. The ambiguity is the local time as it appeared on my watch at the moment the data was added. Sometimes that matters and sometimes it doesn’t.
When does it matter? A number of items like resting heart rate are recorded once per day. But because of time zone issues, you can end up with two on one day and none on another. Also, there may be situations where you want to look at patterns over the course of a day. At one point I wanted to look at whether there were periods when my heart rate was unusually high during normal sleeping hours. I looked for a heart rate above 120 between the hours of 11PM and 6AM. I got hits for when I was hiking in a different time zone because the time stamp appeared to be during those night time hours when in fact the local time was shifted five or seven hours because of the different time zone.
The time stamp issues are tricky. If these kinds of situations are not a problem for you, then ignore them and skip this section. Your life will be simpler.
I use the lubridate package to deal with the time stamps. R relies on a Unix-based standard for dates and time called POSIX that is implemented as a class called POSIXct. You can see lots of references to POSIXct in the lubridate documentation. The as_datetime function in lubridate allows you to add a tz parameter that specifies the time zone. A significant difficulty is that in R the time zone is stored as an attribute of the vector rather than as part of the data. If you have a vector of datetime data, the time zone attribute applies to the entire vector, not to individual elements in the vector. If you want to store time zones that vary within the vector, you need to store them in a separate vector, and that’s not part of the R standard for handling dates and times. You’re on your own. The lubridate package includes some functions to help convert vectors from one time zone to another and to deal somewhat with daylight savings. But it does not automatically help with a vector that contains datetime information from varying time zones (as well as different daylight savings issues). (See Clayton Yochum for a more detailed discussion of general time zone messiness in R.)
As I searched the web for tips on how to approach this issue, I discovered that there’s a population of people who are working hard to maintain a streak in filling their activity rings in the Apple Activity app. Some of those individuals get frustrated because they are tripped up by movement across time zones or even changes to daylight savings. There are a number of tips out there for activity tracking in the face of crossing time zones.
My Treatment of Time Zones and the Apple Health Export
Here I describe the way I handled the time zone issue. There will be three steps.
1. Identify when I was in a different time zone.
2. Attach a time zone to each row of health_df.
3. Use the time zone information to attach a local start and end time to each observation.
The first task is to figure out when I was outside of my home time zone. To do that I need a data frame that shows me the time when I arrived in another time zone. I created a table that contains the date and time my watch switched to a new time zone. In my case that means identifying airplane trips that landed in a different time zone. As a bonus, I will describe in detail how I used data exported from TripIt to create most of the table of time zone changes. Later I converted that information to UTC and then used the table to establish the time zone in each of my 4+ million rows of data from the Apple Health Export.
My TripIt data is missing one overseas trip. I needed to add that trip manually. Here is a tribble that creates a table to describe a trip to Greece via a two day stop in Amsterdam. If you have no data in TripIt then the manual table would have to describe all your trips to a different time zone.
manual_timezone_changes <-
tibble::tribble(
~local_arrive, ~local_timezone,
"2018-04-18 09:15:00", "Europe/Amsterdam",
"2018-04-20 21:00:00", "Europe/Athens",
"2018-04-30 15:23:00", "America/New_York"
) %>%
mutate(local_arrive = as_datetime(local_arrive))The local_arrive column records when I arrived in a new time zone and is the scheduled arrival time for the fight to that time zone. For example, the first line represent a flight that I took from JFK to Amsterdam that arrived at 9:15 the next morning in Amsterdam time. My watch was on New York time until I turned off airplane mode after arrival in Amsterdam so I am focusing on the arrival time. One could do similar lines of data for arrivals by car, train, or boat. Later we will see how to transform this data so that it can be applied to the rows of the Apple Health Export. First, let’s go into the details of how to complete this table using data from TripIt.
Using TripIt Data to Track Your Plane Flights
I will use TripIt to get most of my flight information. This was inspired by a talk by Hadley Wickham. The point of the talk was data visualization, but one of his examples was based on relationship between when he is traveling and number of commits on GitHub. For that example he used the history of his trips on TripIt, and that’s the data I need to correct the time stamps.
OK, here we go. Remember that I warned you that adjusting the time stamps would involve complications.
I started with Hadley’s code to fetch history from TripIt. There’s a TripIt developer page that points you to more information. TripIt has an OAuth API for full-strength applications. That was more than I needed. Hadley used a simpler form of authorization. Here’s the TripIt description:
TripIt API offers a very simple way of authenticating the API that should only be used for testing and development purposes…. Note that this authentication scheme is off by default for every TripIt user. If you want to have this turned on for your account so you can use it for development purposes please send email to support@tripit.com.
I sent them an email to request simple authentication, and TripIt support responded the next day. From then on I could use httr functions to get the data from TripIt via information from documentation of the TripIt API.
I did one GET call from httr to get a list of my TripIt trips. Next I used the purrr package to extract data from the nested JSON lists returned by TripIt. In particular, I used the map function to get TripIt “air” objects for each trip ID. Individual airplane flights are “segments” with each air object. For example, a trip might be two connecting flights to get to the destination and two flights to return home, each represented by a “segment”. I always feel like I’m a few steps away from thorough understanding of purrr and tend to rely on a certain amount of trial and error to get a sequence of flatten and map call that extract what I need. The code is available from a GitHub repo I made to support this post.
I end up with a data frame that has the scheduled departure and arrival for each flight and conveniently provides the time zone for each airport. Note that in practice this data might not be perfect. It is scheduled flights only and would not account for cancelled flights or even the time of a delayed flight. So keep that in mind before you try to use this data to examine something detailed such as whether your heart rate is elevated during takeoffs and landings.
I took a quick detour and explored whether I could use the FlightAware API to get the actual arrival times. It is now easy to get free access to limited FlightAware data. But the API calls are oriented to retrieving current rather than historical data so I can’t use it to find out about my past flights.
Once I have the trip ID’s, I use trip ID to fetch the flight information. I used the RStudio View() function to examine the results I got back from calls to the TripIt API. I get one trip at a time, fetch the air segments, and then bind them together with purrr::map_dfr. I fetched more than the minimum columns I needed partly out of curiosity over what was in the TripIt data. It’s interesting to see all my flight information in one table, although much is not directly relevant to the task at hand.
# get list of trips
trips_list <- GET_tripit("https://api.tripit.com/v1/list/trip/past/true/false")
trip_ids <- trips_list$Trip %>% map_chr("id")GET_air <- function(trip_id) {
atrip <-
GET_tripit(
paste0(
"https://api.tripit.com/v1/get/trip/id/",
trip_id,
"/include_objects/true"
) )
air_trip <- atrip[["AirObject"]][["Segment"]]
flights <- dplyr::tibble(
trip_id = trip_id,
trip_start = atrip[["Trip"]][["start_date"]],
start_date = air_trip %>% purrr::map("StartDateTime") %>% map_chr("date"),
start_time = air_trip %>% purrr::map("StartDateTime") %>% map_chr("time"),
start_timezone = air_trip %>% purrr::map("StartDateTime") %>% map_chr("timezone"),
start_city = air_trip %>% purrr::map_chr("start_city_name"),
end_date = air_trip %>% purrr::map("EndDateTime") %>% map_chr("date"),
end_time = air_trip %>% purrr::map("EndDateTime") %>% map_chr("time"),
end_timezone = air_trip %>% purrr::map("EndDateTime") %>% map_chr("timezone"),
end_city = air_trip %>% purrr::map_chr("end_city_name"),
airline = air_trip %>% purrr::map_chr("marketing_airline"),
code = air_trip %>% purrr::map_chr("marketing_airline_code"),
number = air_trip %>% purrr::map_chr("marketing_flight_number"),
aircraft = air_trip %>% purrr::map_chr("aircraft_display_name"),
distance = air_trip %>% purrr::map_chr("distance"),
duration = air_trip %>% purrr::map_chr("duration")
)
}
GET_air_mem <- memoise::memoise(GET_air)
# I used memoise because TripIt typically doesn't let me fetch
# all the data in a single call. With memoise, for each call
# I only fetch the items it doesn't remember.flying <- trip_ids %>% map_dfr(GET_air_mem)I used memoise with the GET_air_mem function because TripIt generally doesn’t give me all my flights on one try. It seems to limit how much data it will return. Because of memoise the Get_air_mem remembers the results of previous successful fetches from TripIt and only asks for things flights it doesn’t already know about.
I ended up with a tibble with one row per flight. I selected the two columns I needed and used bind_rows to combine them with the manual data I created above. I focused on the ending time and location of each flight. That’s when I assume my watch gets changed to a new time zone and life in that time zone begins. Life in that time zone ends when life in the next time zone begins. I wrote a short function to convert the local scheduled time in the flight information into UTC time comparable to what is in the health export.
So after I bind together rows from TripIt and the manual rows above, I set utc_until = lead(utc_arrive), until_timezone = lead(local_timezone). I set the last utc_until to now()
local_to_utc <- function(dt, timezone) {
# UTC of this local time. Note: not vectorized
if (is.character(dt)) dt <- as_datetime(dt)
tz(dt) <- timezone
xt <- with_tz(dt, "UTC")
tz(xt) <- "UTC"
return(xt)
}
arrivals <- flying %>%
mutate(local_start = ymd_hms(paste0(start_date, start_time)),
local_arrive = ymd_hms(paste0(end_date, end_time))) %>%
filter(start_timezone != end_timezone) %>% # only trips that change time zone matter
select(local_arrive, local_timezone = end_timezone) %>%
# manual additions here
bind_rows(manual_timezone_changes) %>%
mutate(utc_arrive = map2_dbl(local_arrive, local_timezone, local_to_utc) %>% as_datetime) %>%
arrange(utc_arrive) %>%
mutate(utc_until = lead(utc_arrive), until_timezone = lead(local_timezone))
arrivals$utc_until[nrow(arrivals)] <- with_tz(now(), "UTC")
arrivals$until_timezone[nrow(arrivals)] <- Sys.timezone() # I don't really need this.
# Check that I have arrivals set up properly so that my last arrival is in my home time zone, otherwise warn
if (arrivals$local_timezone[nrow(arrivals)] != Sys.timezone()) warning("Expected to end in Sys.timezone:",
Sys.timezone(), " rather than ",
arrivals$local_timezone[nrow(arrivals)])Assign a Time Zone to Each Row of the Data
The next step was to associate a time zone with each of the 4+ million rows in health_df. I thought this would be difficult and very slow. I was wrong! The fuzzyjoin package by Dave Robinson came to the rescue. I can’t do a simple join between flights and data rows because there is not an exact match for the time stamps. Instead I want to join the time stamps in health_df with a start and end time stamp for each row in the arrivals table. It turns out fuzzyjoin has that covered.
The fuzzyjoin package provides a variety of special joins that do not rely on an exact match. In this case, what I needed was the interval_left_join function which joins tables based on overlapping intervals. The help for interval_left_join explains that this function requires the IRanges package available from Bioconductor and points to instructions for installation. This was the first time I have used anything from the Bioconductor repository. I’m impressed by the speed of interval_left_join. I thought it would be impractical to run it on the full dataset, but it feels fast. I also used it to relate rows in health_df to rows in workout_df, but I’ll describe that in Part II.
health_df <- health_df %>%
mutate(utc_start = as_datetime(startDate),
utc_end = as_datetime(endDate)) %>%
filter(!is.na(utc_start)) %>%
interval_left_join(arrivals %>%
select(utc_arrive, utc_until, timezone = local_timezone),
by = c("utc_start" = "utc_arrive", "utc_start" = "utc_until"))Do a quick report to check whether the assignment of time zone makes sense. If data documenting the transition from one time zone to another is missing the whole table will be off kilter. If there’s something wrong with the arrivals table, it should show up as an unexpected result in Table 2.
# shows trip by trip to check whether timezone assignment works as expected:
# health_df %>% #filter(timezone != "America/New_York") %>%
# mutate(date = as_date(utc_start)) %>%
# group_by(timezone, utc_arrive) %>% summarise(arrive = min(utc_start), leave = max(utc_start),
# days = length(unique(date)),
# n = n())
# Do a quick check whether the distribution of time zones makes sense
health_df %>% mutate(date = as_date(utc_start)) %>% group_by(timezone) %>%
summarise(dates = length(unique(date)), observations = n()) %>%
kable(format.args = list(decimal.mark = " ", big.mark = ","),
table.attr='class="myTable"',
caption = "Frequency of Days by Time Zone")Table 2: ?(caption)
| timezone | dates | observations |
|---|---|---|
| America/Chicago | 19 | 19,435 |
| America/Los_Angeles | 15 | 25,836 |
| America/New_York | 2,198 | 2,844,369 |
| America/Phoenix | 20 | 10,535 |
| Europe/Amsterdam | 3 | 5,105 |
| Europe/Athens | 11 | 19,555 |
| Europe/London | 29 | 60,382 |
| Europe/Rome | 14 | 1,467 |
Using Row-by-Row Time Zone Data to Adjust Time Stamps
Now that I have time zone information attached to each row of health_df, I can translate the UTC time into the local time as it appeared on my watch. In practice I find it quite hard to wrap my head around exactly what is happening with all these time manipulations. Sometimes it feels like a science fiction time travel story2.
Remember that for the datetime class in R, time zone is an attribute that applies to an entire vector. That’s a limitation we need to work around. First we will convert the character version of the time stamp (with universal time offset) to a datetime class value with UTC as the time zone.
Next I create a function exported_time_to_local which will convert the time as it appears in the Apple Health Export to the time as it appeared at the time the data was originally added to the health data. As a side effect the lubridate conversion functions will also adjust for daylight savings changes. This function will apply to data for a single time zone only so that it can be vectorized. This is important because it will be applied to millions of rows.
utc_dt_to_local <- function(dt, time_zone) {
# Adjust a vector of datetime from time zone where data was exported
# to a particular time_zone that that applies to the whole vector.
tz(dt) <- "UTC"
local <- with_tz(dt, time_zone) # now adjust utc to the time zone I want
tz(local) <- "UTC"
# I mark the vector as UTC because I will be row_bind-ing vectors
# together and all need to have the same time zone attribute.
# Although the vector is marked as UTC,
# in the end I will treat the hour as being whatever the local
# time was that I experienced then.
return(local)
}Next I will apply the utc_dt_to_local function to the character time stamps in the Apple Health Export. The function needs to be applied to a vector with the same time zone for all elements in the vector. By doing group_by(start_time_zone) before I use the function inside mutate, the function will be applied with a different time zone for each group. That way the function is vectorized for each group and is reasonably fast. I did not group the time zones separately for the start date and the end date. Usually they would be in the same tine zone, and even if they are not I want to handle them as if they were. All the time stamp vectors end up having the time zone attribute of “UTC”. Remember that time zone is a single attribute that has to apply to the whole vector. In this case it is labelled UTC, but each time stamp describes the local time when and where the observation was recorded. So 16:42 means 4:42 PM in the time zone (and daylight savings status) at the place and time of the measurement that goes with that time stamp.
health_df <- health_df %>%
group_by(timezone) %>%
# assume end_date is in the same time zone as start_date
mutate(local_start = utc_dt_to_local(utc_start, first(timezone)),
local_end = utc_dt_to_local(utc_end, first(timezone))) %>%
# mutate(end_time_zone = get_my_time_zone(endDate)) %>%
# group_by(end_time_zone) %>%
# mutate(end_date = exported_time_to_local(endDate, first(end_time_zone))) %>%
ungroup() %>%
mutate(date = as_date(utc_start),
start_time = as.integer(difftime(local_start, floor_date(local_start, "day"), unit = "secs")) %>% hms::hms()) %>%
arrange(type, utc_start) %>%
ungroup()
# Here I'll adjust time for workout_df as well
workout_df <- workout_df %>%
mutate(utc_start = as_datetime(startDate),
utc_end = as_datetime(endDate)) %>%
filter(!is.na(utc_start)) %>%
interval_left_join(arrivals %>%
select(utc_arrive, utc_until, timezone = local_timezone),
by = c("utc_start" = "utc_arrive", "utc_start" = "utc_until"))
workout_df <- workout_df %>%
group_by(timezone) %>%
mutate(local_start = utc_dt_to_local(utc_start, first(timezone)),
local_end = utc_dt_to_local(utc_end, first(timezone))) %>%
arrange(utc_start) %>%
ungroup()
# I'm going to focus on health_df and workout_df, but I could adjust times in the other df's as wellAt this point we have two sets of date and time stamps for health_df and workout_df. The prefix “utc” is for universal time and should be used for sorting by time. The prefix “local” has local time as was shown on the watch when the measurement was recorded. Local time and date is what we need if we want to examine time during the day. For health_df there is also a column called start_time which is just the time of day, without date, expressed as hh:mm:ss.
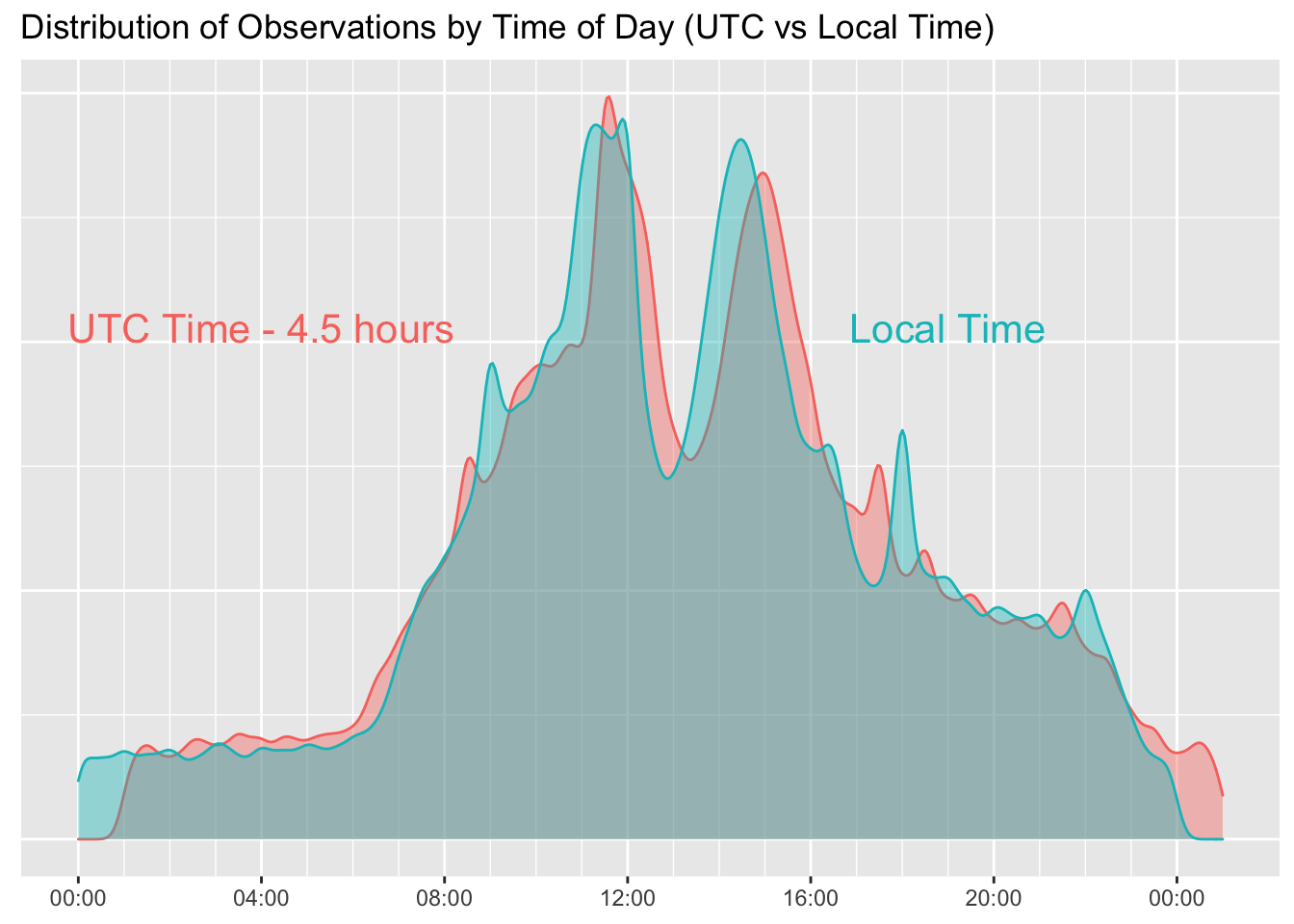
Figure 1 is a density plot that shows the difference between looking at time of day in terms of UTC versus local time. The first takeaway from this plot is that the frequency of measurements is strongly related to time of day. There are relatively few measurements during the night period when I am usually asleep in bed. There is also a deep dip around lunch time. The Apple Watch makes more measurements when I am being active. I’ll look at that in more detail in Part II.
The two distributions (UTC and local time) mostly overlap, but there are some systematic differences. I live in the Eastern Time Zone which is five hours later than UTC during standard time and four hours later during daylight savings. As a compromise I subtracted 4.5 hours from the UTC time of day to make the distributions fit on the same scale. The red scale shows the distribution of observations in the export data in terms of UTC time of day and the blue scale shows local time. The blue scale corresponds more to my subjective experience of time of day. You can see that the red distribution is “fatter” during the period from 4AM to 8AM than is the blue scale. That’s primarily because of walking trips in England that are not in the Eastern Time. Observations that appear to be at 4AM in terms of UTC - 4.5 are probably happening in British Summer Time (because I’m on a hike in England during the summer) which is actually UTC + 1. In terms of my experience of local time, they are happening when my watch says 9AM. (The dataset also includes a 10 day walking holiday in Greece which is another two hours farther east than England.)
If one looks at sleep time between 00:00 and 06:00, the Local Time distribution (blue) shows a consistent pattern of fewer observations because of less activity. A larger proportion of my activity outside of the Eastern Time Zone was in Europe rather than in Pacific Time and that’s why the UTC distribution seems shifted to the left relative to Local Time. Also, Local Time is responding to daylight savings changes and UTC is not. I think that explains why the peaks before and after lunch time are higher in the Local Time distribution than in UTC. I’m actually fairly rigid about when I take time for lunch (and presumably reduce my physical activity) and taking daylight savings into account makes that more clear.
In summary, if I did not correct for time zone and daylight savings the general bi-modal pattern would still be apparent. But the translation into local time makes the time of day pattern more clear and more accurate, especially if one focuses on hours when I would expect to be asleep.
Apple, If You’re Listening…
There may be a relatively simple item of data that Apple could add to the health data that would make it easier (and more accurate) to execute the adjustments for time zone described in this post. Whenever time zone on the watch or phone is changed, surely there is a log of that event. If those change events were added to the health dataset as a separate item, then one could construct an effective way to adjust all the time stamps in the datasets, similar to the way I have used the flight arrival times. I don’t know whether there are logs to accomplish this retrospectively, but even if it were added going forward that would be a big help. It would add very little data to the database. Travel and daylight savings are the only events that cause me to change the time on my phone or watch. Perhaps there are some unusual situations where someone lives close to the border of a time zone where they frequently change among cell phone towers in different time zones. Perhaps that would add a lot more time change data, but such a person really needs a way to adjust for time zone even more than most people. The fancy solution from Apple would be if they added time change events to the data and then used that data to adjust the UTC offset at the time they produced the Apple Health Export. That would be a great help and make the data less confusing. In that case the time zone offsets that already appear in the exported data would actually mean something useful and would allow easy translation between UTC and local time.
Conclusion
This ends Part I. I decided I need to do a separate Part I because this is mostly about the machinations to adjust time stamps to retrieve local time. But for most people that’s an issue that can be ignored, meaning the bulk of Part I is not relevant for most people. In Part II I will examine some of the data elements in more detail and give some examples using the data.
Footnotes
The documentation for the Apple Health Kit does offer a way for developers to store time zone meta data via the
HKMetadataKeyTimeZoneobject. It appears that not even Apple uses this feature. And the Apple documentation only suggests using it for sleep data. It would be impractical to try to attach this meta data to every single observation.↩︎For the ultimate in time travel paradox, see Heinlein’s All You Zombies, described here. There’s a movie version called Predestination starring Ethan Hawke.↩︎