Scraped stats from Ukraine Ministry of Defense on Russian losses.
Author
John Goldin
Published
May 26, 2023
Modified
2025-02-14
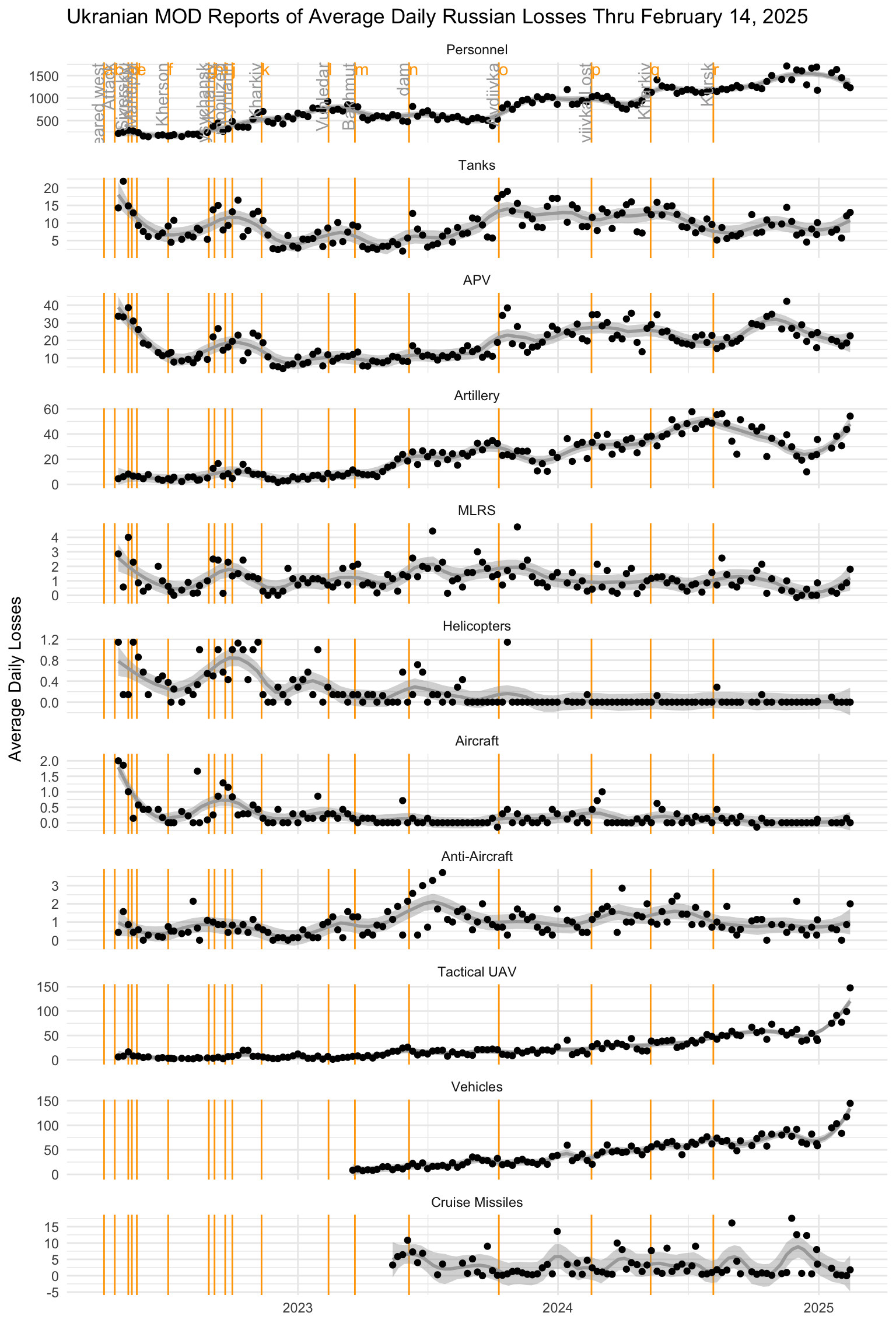
Each day the Ministry of Defence of Ukraine publishes a summary of Russian combat losses since the beginning of the Russian invasion. Daily reports presented in a fairly constant format go back to April of 2022.
This blog post provides a simple plot to track the losses as reported by the MOD. I’ve used R to download those reports and summarize them. I’m sure many others have done something similar.
In January 2024 I was no longer able to get the casualty reports from the MOD site. I think Ukraine is posting them on Factbook, but I’m not a Factbook user. I did find a Ukrainian publication that seems to be posting the reports, so I’m now using the data from that site.
The Ministry of Defence of Ukraine has been reporting a summary of Russian losses each day, including a graphic version like this:
Russian losses reported by Ukraine Ministry of Defence
The plot below summarizes the data in the Ministry of Defence reports of Russian losses up through February 14, 2025. It reports the average daily losses for each week. (Note that the last data point in the series may be based on a partial week.)
R code which scrapes data from Ministry of Defense of Ukraine
# using: https://www.scrapingdog.com/blog/web-scraping-r/# link <- "https://www.mil.gov.ua/en/news/2023/03/08/the-total-combat-losses-of-the-enemy-from-24-02-2022-to-08-03-2023/"## page = read_html(link, as_html = FALSE)# lines <- read_html(link)## former location of links:# https://www.kmu.gov.ua/en/news/zahalni-boiovi-vtraty-protyvnyka-z-24022022-po-02012024# once ukraine_functions.R has been sourced, use the following line to update"# update_ukr_mod_df("ukr_mod_df.RData", save_fname_ukr_mod_df = "ukr_mod_df.RData", days_previous = 15) |> print()############################################################################# These functions find the URL's for the Ukraine MOD daily reports and# parset the reports. The counts of losses are tabulated in the data frame# ukr_mod_df. To update that data frame, execute in the console# update_ukr_mod_df("ukr_mod_df.RData")############################################################################# directory that contains the saved ukraine dataukraine_folder <- fs::path_home("R_local_repos", "ukrainestats")local_fetch_date <- lubridate::ymd("2023-05-01") # date when html available in local_fetch_folderlocal_fetch_folder <- fs::path_home("R_local_repos", "ukrainestats", "ukr_reports")cripo_date <- lubridate::ymd("2024-01-25") # date when html exists at cripo.com.ua (data obtained from Facebook, I think)if (1==2) {############################################################################# Run the next line to update the data in ukr_mod_df.RData.############################################################################update_ukr_mod_df("ukr_mod_df.RData", days_previous =10)}library(tidyverse)library(glue)library(xml2)#' Extract the casualty count from a line in the report based on a regex search#'#'#'#' @param text The text of the web page that contains the casualty report.#' @param phrase The regex that will find the casualty number.#'#' @return The casualty number.#' @export#'#' @examples#' x <- str_extract(text, "(?<=personnel [‒-] about )[\\d,]*")extract_number <-function(text, phrase ="(?<=personnel [‒-] about )[\\d,]*") {# In regular expressions, \D is a shorthand character class that matches any character that is not a digit.# It's the opposite of \d, which matches any digit (0-9).if (str_detect(text, intToUtf8(160))) text <-str_replace_all(text, intToUtf8(160), " ") extracted_number <-str_extract(text, phrase) |>str_replace_all("\\D", "") # \\D is a shorthand character class that matches any character that is not a digit.if (is.na(extracted_number)) {#if (!str_detect(text, phrase)) stop(paste0(phrase, "\nnot found in\n", text))warning(paste0("number not found while looking for: ", phrase, "\n", text))return(NA_real_) }as.numeric(extracted_number)}# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # ### Notes on scraping and parsing the data on Russian losses from the# Ukraine Ministry of Defense web site:## April 12, 2022 is earliest Russian casualty count## Some dates that are missing data: "2022-06-16", "2022-06-18" (others in June)## at this point doing two digit date for start of war and end# https://www.mil.gov.ua/en/news/2023/02/23/the-total-combat-losses-of-the-enemy-from-24-02-22-to-23-02-23/## back then two digit years# https://www.mil.gov.ua/en/news/2022/12/16/the-total-combat-losses-of-the-enemy-from-24-02-to-16-12/## https://www.mil.gov.ua/en/news/2022/12/31/the-total-combat-losses-of-the-enemy-from-24-02-to-31-12/## 3/3/2023 seems to be start of using 4-digit year## wrong:# https://www.mil.gov.ua/en/news/2022/09/23/the-total-combat-losses-of-the-enemy-from-24-02-to-23-09/## On January 1, started doing two digit dates# https://www.mil.gov.ua/en/news/2023/01/03/the-total-combat-losses-of-the-enemy-from-24-02-22-to-03-01-23/## works# https://www.mil.gov.ua/en/news/2023/02/20/the-total-combat-losses-of-the-enemy-from-24-02-22-to-20-02-23/## does not work:# https://www.mil.gov.ua/en/news/23/02/23/the-total-combat-losses-of-the-enemy-from-24-02-22-to-23-02-23/## does note work:# https://www.mil.gov.ua/en/news/23/02/20/the-total-combat-losses-of-the-enemy-from-24-02-22-to-20-02-23/## works:# https://www.mil.gov.ua/en/news/2022/05/09/the-total-combat-losses-of-the-enemy-from-24-02-to-09-05/## works:# https://www.mil.gov.ua/en/news/2022/06/25/the-total-combat-losses-of-the-enemy-from-24-02-to-25-06/## works:# https://www.mil.gov.ua/en/news/2022/04/16/the-total-combat-losses-of-the-enemy-from-24-02-to-16-04/## first phrase changed between 2022-04-16 and 2022-04-17# "personnel ‒ about" to### wrong:# https://www.mil.gov.ua/en/news/2022/07/12/the-total-combat-losses-of-the-enemy-from-24-02-to-12-07/## wrong:# https://www.mil.gov.ua/en/news/2022/06/20/the-total-combat-losses-of-the-enemy-from-24-02-to-20-06/## More than one line found 2022-06-06 and that goes until 2022-07-26 when hits error## New style of URLs at Governmental Portal (rather than MOD website)# https://www.kmu.gov.ua/en/news/zahalni-boiovi-vtraty-protyvnyka-z-24022022-po-04012024/## Starting at some point in late 2023, reports have been moved to the Governmental Portal (kmu.gov.ua)# rather than MOD website (mil.gov.ua). The Governmental Portal does not allow me to use# read_lines to## In December the casualty reports began to appear on the Governmental Portal (kmu.gov.ua).# Because I had difficulty using read_lines to scrape the data from the Governmental Portal,# I created an AppleScript script to download the html to my local disk at local_fetch_folder.# The date when these html files become available is local_fetch_date.## But posting them at the kmu.gov.ua portal didn't last long. Now they seem to be on Facebook.# I had to find a Ukrainian publication that continued to reproduce them.# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # ## there's a gap in the English URL's. They start again with 2023/09/27# gap is 2023/09/13 to 2023/09/26# URLs of casualty report pages in Ukrainian# This is no longer needed. All these are now available in local_fetch_folder.in_ukraine_urls <-c("https://www.mil.gov.ua/news/2023/09/13/ponad-270-tisyach-vijskovih-vtratila-armiya-rf-za-567-dniv-agresii-proti-ukraini-–-genshtab-zsu/","https://www.mil.gov.ua/news/2023/09/14/vid-pochatku-shirokomasshtabnoi-vijni-proti-ukraini-rosiya-vtratila-uzhe-ponad-270970-osib-znishheno-pidvodnij-choven-voroga-–-genshtab-zsu/","https://www.mil.gov.ua/news/2023/09/15/zagalni-vtrati-rosijskih-zagarbnikiv-stanovlyat-271-4-tis-osib-znishheno-ponad-5-970-artsistem-voroga-genshtab-zsu/","https://www.mil.gov.ua/news/2023/09/16/za-dobu-sili-oboroni-znishhili-16-artsistem-i-4-tanki-voroga-zagalni-vtrati-rf-stanovlyat-271-790-osib-–-genshtab-zsu/",#"https://www.mil.gov.ua/news/2023/09/17/vid-pochatku-shirokomasshtabnoi-vijni-proti-ukraini-rosiya-vtratila-uzhe-ponad-272-300-osib-znishheno-4-620-tankiv-voroga-–-genshtab-zsu/",# there's space in personnel number"https://www.mil.gov.ua/news/2023/09/18/ukrainski-zahisniki-za-dobu-likviduvali-620-okupantiv-znishhili-24-artsistemi-i-6-bbm-genshtab-zsu/","https://www.mil.gov.ua/news/2023/09/19/zagalni-vtrati-rosijskih-zagarbnikiv-stanovlyat-273-4-tis-osib-znishheno-ponad-6-060-artsistem-voroga-genshtab-zsu/","https://www.mil.gov.ua/news/2023/09/20/za-dobu-sili-oboroni-znishhili-34-artsistemi-i-37-bpla-operativno-taktichnogo-rivnya-voroga-zagalni-vtrati-rf-stanovlyat-orientovno-273-980-osib-genshtab-zsu/","https://www.mil.gov.ua/news/2023/09/21/ukrainski-zahisniki-za-dobu-likviduvali-490-okupantiv-znishhili-41-artsistemu-i-15-bbm-voroga-genshtab-zsu/","https://www.mil.gov.ua/news/2023/09/22/ukrainski-zahisniki-za-dobu-likviduvali-480-okupantiv-znishhili-40-artsistem-i-8-bbm-voroga-genshtab-zsu/","https://www.mil.gov.ua/news/2023/09/23/ukrainski-zahisniki-za-dobu-likviduvali-510-okupantiv-znishhili-33-artsistemi-i-21-bbm-voroga-genshtab-zsu/","https://www.mil.gov.ua/news/2023/09/24/vid-pochatku-shirokomasshtabnoi-vijni-proti-ukraini-rosiya-vtratila-blizko-275-850-osib-znishheno-4-662-tanka-voroga-–-genshtab-zsu/","https://www.mil.gov.ua/news/2023/09/25/ukrainski-zahisniki-za-dobu-likviduvali-420-okupantiv-znishhili-27-artsistem-i-13-bbm-genshtab-zsu/",'https://www.mil.gov.ua/news/2023/09/26/ukrainski-zahisniki-za-dobu-likviduvali-400-okupantiv-znishhili-39-artsistem-i-19-bbm-genshtab-zsu/')# "https://www.mil.gov.ua/news/2023/09/27/vid-pochatku-shirokomasshtabnoi-vijni-proti-ukraini-rosiya-vtratila-uzhe-majzhe-277-tis-osib-znishheno-534-zasobiv-ppo-voroga-–-genshtab-zsu/",# "https://www.mil.gov.ua/news/2023/09/28/zagalni-vtrati-rosijskih-zagarbnikiv-stanovlyat-277-3-tis-osib-znishheno-ponad-8800-odinicz-avtotehniki-ta-avtoczistern-voroga-‒-generalnij-shtab-zsu/")# code suggested by bard to extract datepattern_ukrainian_personnel <-"особового складу? ?[‒–—-][ \u00A0]близько? ((?:\\d+\\s*)+)|особового складу [‒–—-][ \u00A0]((?:\\d+\\s*)+)"#str_replace_all(pattern_ukrainian_personnel, " ", str_c(intToUtf8(160), " "))key_phrase <-"особового складу ?[‒–—-]"# # Load the httr2 package# library(httr2)## # Create a function to test if a web page is in Ukrainian# # function created by Bard# is_ukrainian <- function(url) {# # Make a request to the web page# response <- request(url) %>% req_perform()## # Get the content type of the response# content_type <- response$headers$`Content-Type`## # If the content type is HTML, extract the language code from the meta tags# if (startsWith(content_type, "text/html")) {# language_code <- html_meta(response$body, "lang")## # Return TRUE if the language code is Ukrainian, FALSE otherwise# return(language_code == "uk")# } else {# # If the content type is not HTML, return FALSE# return(FALSE)# }# }# # Test if the web page in the string "aurl" is in Ukrainian# is_ukrainian("https://www.pravda.com.ua/")# ##' Create a URL that goes to a standard Russian casualty report#'#' @param adate The Date for the report.#'#' @return String with the URL for the casualty report.#' @export#'#' @examplescreate_ukr_mod_link <-function(adate, old_style =FALSE) {if (!is.Date(adate)) adate <-as_date(adate)if (is.na(adate)) {warning(paste0(adate, "is not a valid date.[increate_ukr_mod_link]"))return("") }# must have this form: (4 digit years)# https://www.mil.gov.ua/en/news/2023/03/08/the-total-combat-losses-of-the-enemy-from-24-02-2022-to-08-03-2023/## format at end of September:## https://www.mil.gov.ua/en/news/2023/09/29/the-total-combat-losses-of-the-enemy-from-24-02-2022-to-29-09-2023/# https://www.mil.gov.ua/en/news/2023/09/28/the-total-combat-losses-of-the-enemy-from-24-02-2022-to-28-09-2023/## Reports moved from MOD to www.kmu.gov.ua starting 2023-06-21 url_moved <-as_date("2023-06-21")if ((adate > cripo_date) & (adate <=today())) { link <-glue("https://cripo.com.ua/news/war/generalnyj-shtab-zsu-informuye-pro-vtraty-voroga-na-", format(adate, "%d-%m-%y"), "/") }elseif ((old_style & (adate < url_moved)) | (adate < url_moved)) {if (adate >as_date("2022-09-01")) link <-glue("https://www.kmu.gov.ua/en/news/zahalni-boiovi-vtraty-protyvnyka-z-24022022-po-", format(adate, "%d%m%Y"),"/")if (adate ==as_date("2023-03-30")) link <-"https://www.mil.gov.ua/en/news/2023/03/30/blizko-173-tis-osib-znishheno-ponad-6970-bojovih-bronovanih-mashin-voroga-–-genshtab-zsu/"elseif (adate >=as_date("2023-03-03")) link <-glue("https://www.mil.gov.ua/en/news/", format(adate, "%Y/%m/%d"), "/the-total-combat-losses-of-the-enemy-from-24-02-2022-to-", format(adate, "%d-%m-%Y"), "/")elseif (adate >=as_date("2023-01-01")) link <-glue("https://www.mil.gov.ua/en/news/", format(adate, "%Y/%m/%d"), "/the-total-combat-losses-of-the-enemy-from-24-02-22-to-", format(adate, "%d-%m-%y"), "/") }else { link <-glue("https://www.kmu.gov.ua/en/news/zahalni-boiovi-vtraty-protyvnyka-z-24022022-po-", format(adate, "%d%m%Y"),"/") } link}#' Extract the lines from a Ukraine Ministry of Defense page that contain the Russian casualty counts#'#' @param adate Date of casualty report on Ukraine Ministry of Defense web site#' @param fetch_image_url Fetch the URL that displays the report as an image.#'#' @return List of text lines that contain the casualty reports, each category on different line.#' @export#'#' @examples#' fetch_ukr_mod_text("2023-03-29")#' fetch_ukr_mod_text("", known_url = "https://www.mil.gov.ua/news/2023/09/17/vid-pochatku-shirokomasshtabnoi-vijni-proti-ukraini-rosiya-vtratila-uzhe-ponad-272-300-osib-znishheno-4-620-tankiv-voroga-–-genshtab-zsu/")#' xx <- fetch_ukr_mod_text("", known_url = in_ukraine_urls[2])#' xx <- fetch_ukr_mod_text("", known_url = "ukr_reports/ukraine_stats_2024-02-20.txt")#'fetch_ukr_mod_text <-function(adate, fetch_image_url =FALSE, known_url =NULL, ukrainian =FALSE) {# fed either a date or a URLif (!is.Date(adate)) adate <-as_date(adate)if (!is.null(known_url)) { link <- known_url adate <-str_extract(known_url, pattern ="(\\d{4})-(\\d{2})-(\\d{2})") |>ymd() } else {if (adate <ymd("2022-04-12")) return(NA_character_)if (adate >today()) return(NA_character_)# what image line looks like:# himg <- "<a href=\"/assets/images/resources/69849/0b6b4d3834eddf4a9f1c0a30b788ca484d850890.jpg\" class=\"thumbnail\" data-image=\"/assets/images/resources/69849/0b6b4d3834eddf4a9f1c0a30b788ca484d850890.jpg\">"# from chatGPT:# my_string <- "This is a string with start some text end in the middle."## # This regex pattern will extract the text between "start" and "end"# extracted_text <- str_extract(my_string, "(?<=start ).*(?= end)")# str_extract(himg, "(?<=href=\").*(?=\" class)")# keep in mind: stringi::stri_reverse("abcde")# look for: "<base href=\"https://www.mil.gov.ua/en/\" />" link <-create_ukr_mod_link(adate) }if ((adate >= local_fetch_date) & (adate <= cripo_date)) { # after this date, must relyinig on manually downloaded html pages x <-tryCatch({ readr::read_lines(fs::path_home("Documents", "R_local_repos", "ukrainestats", "ukr_reports",glue("ukraine_stats_", format(adate, "%Y-%m-%d"), ".html"))) }, error =function(e) {warning(paste0("For ", adate, " before cripo_date, File not found. "))return(NULL) })if (length(x) ==0) {warning(paste0("For ", adate, " File not found. "))return(NA_character_) } } else { x <-tryCatch({ readr::read_lines(link) }, error =function(e) {warning(paste0("For ", adate, " Link error:", e))return(NULL) })if (length(x) ==0) {warning(paste0("For ", adate, " File not found. "))return(NA_character_) } }# https://www.mil.gov.ua/assets/images/resources/71419/d086b0fc59b7a0a201780cc85201a6ab335ab86c.jpgif (fetch_image_url) {# return an image URL, not casualty data# data-image="/assets/images/resources/71419/d086b0fc59b7a0a201780cc85201a6ab335ab86c.jpg"># image_lines <- x[str_detect(x, "meta property=\"og:image")] image_lines <- x[str_detect(x, "data-image=")]# sample line:# "<a href=\"/assets/images/resources/71419/d086b0fc59b7a0a201780cc85201a6ab335ab86c.jpg\" class=\"thumbnail\" data-image=\"/assets/images/resources/71419/d086b0fc59b7a0a201780cc85201a6ab335ab86c.jpg\">"if (length(image_lines) ==0) return("https://www.mil.gov.ua/assets/images/resources/69817/1ade4ec8f38bbaac946cff911451f14c3f551248.jpg")# extract the image URL from the line# image_url <- str_extract(image_lines[1], "(?<=data-image=\").*(?=\" >)") image_url <-str_extract(image_lines[1], 'class=\"thumbnail\" data-image=\"/assets/images/resources/[0-9]*/.*\\.jpg') image_url <-str_replace(image_url, 'class=\"thumbnail\" data-image=\"', "")# return(str_extract(image_lines[1], "(?<=content=\").*(?=\" />)"))return(paste0( 'https://www.mil.gov.ua/', image_url)) }# image_lines <- x[str_detect(x, "meta property=\"og:image")]# str_extract(image_lines[1], "(?<=content=\").*(?=\" />)")#if (!ukrainian) {# the image of the report is in: x[str_detect(x, "<a href=\"/assets/images/resources/")]#the_line <- x[x |> str_detect("personnel ‒ about")]# the_line <- x[x |> str_detect("The total combat losses of the enemy from")]if (adate <=ymd("2022-04-16")) the_line <- x[str_detect(x, "personnel ‒ about")]if (adate >ymd("2022-04-16")) the_line <- x[str_detect(x, "persons were liquidated")]if (length(the_line) ==0) the_line <- x[str_detect(x, "personnel ‒ about")]if (length(the_line) ==0) the_line <- x[str_detect(x, " ‒ близько/ about")]if (length(the_line) ==0) {if (adate <ymd("2023-09-13")) warning(paste0("Info line not found for ", adate))return(NA_character_) } } else { # known_url so probably Ukranian page# if all else fails, try Ukranian# "https://www.mil.gov.ua/news/2023/09/21/ukrainski-zahisniki-za-dobu-likviduvali-490-okupantiv-znishhili-41-artsistemu-i-15-bbm-voroga-genshtab-zsu/"# the_line <- x[str_detect(x, "особового складу [‒–—-] близьк")]# the_line <- x[str_detect(x, "особового складу [‒–—-]")] the_line <- x[str_detect(x, pattern_ukrainian_personnel)] }if (length(the_line) ==2) the_line <- the_line[1]if (length(the_line) ==0) {warning(paste0("Info line not found for ", adate))return(NA_character_) }if (!ukrainian) {if (adate <=as_date("2022-04-16")) first_line <-which(str_detect(x, "personnel ‒ about"))elseif (adate >as_date("2022-04-16")) first_line <-which(str_detect(x, "persons were liquidated"))if (length(first_line) ==0) first_line <-which(str_detect(x, "personnel ‒ about"))if (length(first_line) ==0) first_line <-which(str_detect(x, " ‒ близько/ about")) } else { # assume Ukrainian first_line <-which(str_detect(x, key_phrase)) }# 2023-04-23 not read because text of report appears twice on the pageif (length(the_line) >1) {warning(paste0(length(the_line), " lines found for ", adate, "\n", link))return(NA_character_) }if (length(first_line) ==0) {stop(paste("In ukraine_functions fetch_ukr_mod_text", "Missing first_line text.", adate)) }if (!ukrainian) last_line <-which(str_detect(x, "special equipment"))else last_line <-which(str_detect(x, "спеціальна техніка"))if (length(last_line) ==2) last_line <- last_line[2]if (is.na(last_line) || (length(last_line) ==0)) last_line <-which(str_detect(x, "vehicles"))if (is.na(last_line) || (length(last_line) ==0)) last_line <-which(str_detect(x, "UAV"))if (length(first_line) ==2) first_line <- first_line[1]if (is.na(last_line) || (length(last_line) ==0)) last_line <- first_line +10# the_linestr_flatten(c(as.character(adate), x[first_line:last_line]))}# str_extract(string, pattern = "(\\d{4})/(\\d{2})/(\\d{2})")# sample report data from early 2024:# personnel ‒ about 363070 (+790) persons,# tanks ‒ 6011 (+9),# APV ‒ 11142 (+14),# artillery systems – 8604 (+30),# MLRS – 949 (+2),# Anti-aircraft warfare systems ‒ 631 (+1),# aircraft – 329 (+0),# helicopters – 324 (+0),# UAV operational-tactical level – 6771 (+18),# cruise missiles ‒ 1786 (+1),# warships / boats ‒ 23 (+0),# submarines - 1 (+0),# vehicles and fuel tanks – 11463 (+40),# special equipment ‒ 1313 (+9).# construct example data for testing parse_ukr_mod_text#' xx <- fetch_ukr_mod_text("", known_url = "ukr_reports/ukraine_stats_2024-02-20.txt")## some_data <- tibble(report = xx, date = ymd("2024-02-20"))# some_additions <- parse_ukr_mod_text(some_data)# most recent example, from https://cripo.com.ua/news/war/generalnyj-shtab-zsu-informuye-pro-vtraty-voroga-na-01-02-24/# особового складу / personnel ‒ близько/ about 386230 (+1000) осіб / persons,# танків / tanks ‒ 6322 (+12) од,# бойових броньованих машин / APV ‒ 11773 (+16) од,# артилерійських систем / artillery systems – 9228 (+33) од,# РСЗВ / MLRS – 976 (+2) од,# засоби ППО / Anti-aircraft warfare systems ‒ 663 (+0) од,# літаків / aircraft – 332 (+0) од,# гелікоптерів / helicopters – 324 (+0) од,# БПЛА оперативно-тактичного рівня / UAV operational-tactical level – 7136 (+36),# крилаті ракети / cruise missiles ‒ 1847 (+1),# кораблі /катери / warships / boats ‒ 23 (+0) од,# підводні човни / submarines – 1 (+0) од,# автомобільної техніки та автоцистерн/ vehicles and fuel tanks – 12267 (+36) од,# спеціальна техніка / special equipment ‒ 1462 (+10)#' Parse the Russian casualty info from Ukraine MOD summary pages.#'#' The text from each web page is in the report column. The extract_number#' function is used to find the casualties for each item, based on a regular expression#' to search for that type of item.#'#' @param mod_df A df which has a report column that contains the text from casualty web pages.#'#' @return The same df is returned, but with numeric columns added for each type of casualty.#' @export#'#' @examplesparse_ukr_mod_text <-function(mod_df) { mod_df$report <-str_replace_all(mod_df$report, intToUtf8(160), " ")# mod_df$personnel = map_dbl(mod_df$report, extract_number, phrase = "(?<=personnel ?[‒–—-] ? ?about (?:близько/ )?)[\\d,]*" ) mod_df$personnel =map_dbl(mod_df$report, extract_number, phrase ="(?<=about )[\\d,]*" ) mod_df$tanks =map_dbl(mod_df$report, extract_number, phrase ="(?<=tanks [‒–—-] )[\\d,]*" ) mod_df$apv =map_dbl(mod_df$report, extract_number, phrase ="(?<=(APV|carrying AFVs) [‒–—-] )[\\d,]*" ) mod_df$artillery =map_dbl(mod_df$report, extract_number, phrase ="(?<=artillery systems [‒–—-] )[\\d,]*" ) mod_df$mlrs =map_dbl(mod_df$report, extract_number, phrase ="(?<=MLRS [‒–—-] )[\\d,]*" ) mod_df$aa =map_dbl(mod_df$report, extract_number, phrase ="(?i)(?<=nti-aircraft (systems |warfare systems )[‒–—-] )[\\d,]*" )# mod_df$aircraft = NA_real_ mod_df$aircraft =map_dbl(mod_df$report, extract_number, phrase ="(?i)(?<=aircraft [‒–—-] )[\\d,]*", .progress =TRUE ) mod_df$helicopters =map_dbl(mod_df$report, extract_number, phrase ="(?<=helicopters [‒–—-] )[\\d,]*" ) mod_df$uav =map_dbl(mod_df$report, extract_number, phrase ="(?<=UAV operational-tactical level [‒–—-] )[\\d,]*" ) mod_df$vehicles =map_dbl(mod_df$report, extract_number, phrase ="(?i)(?<=vehicles and fuel tanks [‒–—-] )[\\d,]*" ) mod_df$special =map_dbl(mod_df$report, extract_number, phrase ="(?i)(?<=special equipment [‒–—-] )[\\d,]*" ) mod_df$warships =map_dbl(mod_df$report, extract_number, phrase ="(?<=warships / boats [‒–—-] )[\\d,]*" ) mod_df$cmissiles =map_dbl(mod_df$report, extract_number, phrase ="(?i)(?<=cruise missiles [‒–—-] )[\\d,]*" ) mod_df# Anti-aircraft warfare systems# anti-aircraft systems#}# parse ukranian# особового складу ‒ близько 273980 (+520) осіб,# танків ‒ 4635 (+7) од,# бойових броньованих машин ‒ 8868 (+17) од,# артилерійських систем – 6096 (+34) од,# РСЗВ – 779 (+1) од,# засоби ППО ‒ 526 (+0) од,# літаків – 315 (+0) од,# гелікоптерів – 316 (+0) од,# БПЛА оперативно-тактичного рівня – 4821 (+37),# крилаті ракети ‒ 1479 (+0),# кораблі/катери ‒ 20 (+0) од,# підводні човни – 1 (+0) од,# автомобільної техніки та автоцистерн – 8633 (+32) од,# спеціальна техніка ‒ 906 (+3).## personnel - about 273,980 (+520) people,# tanks ‒ 4,635 (+7) units,# armored combat vehicles ‒ 8,868 (+17) units,# artillery systems – 6096 (+34) units,# RSZV – 779 (+1) units,# air defense equipment ‒ 526 (+0) units,# aircraft – 315 (+0) units,# helicopters – 316 (+0) units,# UAVs of the operational-tactical level - 4821 (+37),# cruise missiles ‒ 1479 (+0),# ships/boats ‒ 20 (+0) units,# submarines – 1 (+0) units,# automotive equipment and tank trucks - 8633 (+32) units,# special equipment ‒ 906 (+3).parse_ukr_mod_ukraine <-function(mod_df) { temp <- mod_df$report# mod_df$personnel = map_dbl(str_replace_all(mod_df$report, intToUtf8(160), ""), extract_number, phrase = "(?<=особового складу ?[‒–—-] ? ?близько? )[\\d,]*" ) #personnel mod_df$report <-str_replace_all(mod_df$report, intToUtf8(160), " ") mod_df$personnel =map_dbl(mod_df$report, extract_number, phrase = pattern_ukrainian_personnel ) #personnel# mod_df$personnel = map_dbl(mod_df$report, extracted_personnel <- str_extract(the_line, pattern_personnel) |># str_replace_all("\\D", "") mod_df$tanks =map_dbl(mod_df$report, extract_number, phrase ="(?<=танків ?[‒–—-] )[\\d,]*" ) # utf8ToInt("‒-–—") [1] 8210 45 8211 8212 mod_df$apv =map_dbl(mod_df$report, extract_number, phrase ="(?<=бойових броньованих машин ?[‒–—-] )[\\d,]*" ) mod_df$artillery =map_dbl(mod_df$report, extract_number, phrase ="(?<=артилерійських систем ?[‒–—-] )[\\d,]*" ) #prob mod_df$mlrs =map_dbl(mod_df$report, extract_number, phrase ="(?<=РСЗВ ?[‒–—-] )[\\d,]*" ) mod_df$aa =map_dbl(mod_df$report, extract_number, phrase ="(?<=засоби ППО ?[‒–—-] )[\\d,]*" ) mod_df$aircraft =map_dbl(mod_df$report, extract_number, phrase ="(?<=літаків ?[‒–—-] )[\\d,]*" ) mod_df$helicopters =map_dbl(mod_df$report, extract_number, phrase ="(?<=гелікоптерів ?[‒–—-] )[\\d,]*" ) mod_df$uav =map_dbl(mod_df$report, extract_number, phrase ="(?<=БПЛА оперативно-тактичного рівня ?[‒–—-] )[\\d,]*" ) mod_df$vehicles =map_dbl(mod_df$report, extract_number, phrase ="(?<=автомобільної техніки та автоцистерн/? ?[‒–—-] )[\\d,]*" )# mod_df$special = map_dbl(mod_df$report, extract_number, phrase = "(?<=спеціальна техніка ?[‒–—-] )[\\d,]*" ) mod_df$warships =map_dbl(mod_df$report, extract_number, phrase ="(?<=кораблі ?/ ?катери ?[‒–—-] )[\\d,]*" ) mod_df}#' Update the df that contains Ukraine MOD Russian casualty stats#'#' @param fname_ukr_mod_df file name of RData file that contains the stats#'#' @return Returns the updated df but also saves it to an RData file as a side effect.#' @export#'#' @examples#' update_ukr_mod_df("ukr_mod_df.RData", save_fname_ukr_mod_df = "test.RData")#'update_ukr_mod_df <-function(fname_ukr_mod_df, from_date =NULL, to_date =NULL,days_previous =35,ukraine_folder ="/Users/johngoldin/Documents/R_local_repos/ukrainestats/",save_fname_ukr_mod_df =NULL) {if (1==2) {############################################################################# Run the next line to update the data in ukr_mod_df.RData.############################################################################update_ukr_mod_df("ukr_mod_df.RData", save_fname_ukr_mod_df ="ukr_mod_df.RData") }# fname_ukr_mod_df <- "ukr_mod_df.RData"# ukraine_folder <- "/Users/johngoldin/Documents/R_local_repos/ukrainestats/"load(paste0(ukraine_folder, fname_ukr_mod_df))############################################################################# Here's the orginal sequence of dates that was used to initialize ukr_mod_df.# the_dates <- seq(from = ymd("2022-04-15"), to = today(), by = "1 day")############################################################################# dates that need to be added to ukr_mod_dfif (is.null(from_date)) from_date <-today() - days_previousif (is.null(to_date)) to_date <-today() additional_dates <-seq(from = from_date, to = to_date, by ="1 day") new_reports <-map_chr(additional_dates, fetch_ukr_mod_text, .progress =TRUE)# page_additions <- tibble(report = from_ukrainian_urls[!is.na(from_ukrainian_urls)], date = ymd(str_sub(report, start = 1, end = 10))) page_additions <-tibble(report = new_reports, date = additional_dates) |>filter(!is.na(report)) additions <-parse_ukr_mod_text(page_additions)# from map_chr help:# \(x) f(x, 1, 2, collapse = ",")# additions from Ukranian url's rather than english# from_ukrainian_urls <- map_chr(in_ukraine_urls,# \(x) fetch_ukr_mod_text("1950-01-27", known_url = x))# # eliminate any NAs# ukrainian_page_additions <- tibble(report = from_ukrainian_urls[!is.na(from_ukrainian_urls)], date = ymd(str_sub(report, start = 1, end = 10)))# ukrainian_additions <- parse_ukr_mod_ukraine(ukrainian_page_additions)# # ukr_mod_df <- tibble(report = new_reports, date = ymd(str_sub(report, start = 1, end = 10)))# if (length(new_reports > 0)) {# ukr_mod_page_additions <- tibble(report = new_reports, date = ymd(str_sub(report, start = 1, end = 10)))# ukr_mod_additions <- parse_ukr_mod_text(ukr_mod_page_additions)# }# from_ukrainian_urls <- map_chr(in_ukraine_urls,# \(x) fetch_ukr_mod_text("1950-01-27", known_url = x))# # eliminate any NAs# ukrainian_page_additions <- tibble(report = from_ukrainian_urls[!is.na(from_ukrainian_urls)], date = ymd(str_sub(report, start = 1, end = 10)))# ukrainian_additions <- parse_ukr_mod_ukraine(ukrainian_page_additions)# # ukr_mod_df <- tibble(report = new_reports, date = ymd(str_sub(report, start = 1, end = 10)))# if (length(new_reports > 0)) {# ukr_mod_page_additions <- tibble(report = new_reports, date = ymd(str_sub(report, start = 1, end = 10)))# ukr_mod_additions <- parse_ukr_mod_text(ukr_mod_page_additions)# }# use overlap_dates to check whether MOD has updated recent daata# overlap_dates <- bind_rows(ukr_mod_df |> filter((ukr_mod_df$date %in% ukr_mod_additions$date)),# ukr_mod_additions |> filter(ukr_mod_additions$date %in% ukr_mod_df$date)) |># arrange(date) # |> View()# save_ukr_mod__df <- ukr_mod_df# ukr_mod_df <- bind_rows(ukr_mod_df |> filter(!(ukr_mod_df$date %in% ukr_mod_additions$date)), ukr_mod_additions) ukr_mod_df <-bind_rows(ukr_mod_df |>filter(!(date %in% additions$date)), additions)# fix possible typo in one url pageif(ukr_mod_df$artillery[ukr_mod_df$date ==ymd("2024-02-27")] ==1009) { ukr_mod_df$artillery[ukr_mod_df$date ==ymd("2024-02-27")] <-10009 }# calculate the number of days between each row ukr_mod_df <- ukr_mod_df |>arrange(date) |>mutate(gap =as.numeric(date -lag(date, default = ukr_mod_df$date[1] -1)))# by default, save it back into the save file that it was loaded fromif (is.null(save_fname_ukr_mod_df)) save_fname_ukr_mod_df <- fname_ukr_mod_dfsave(ukr_mod_df, file =paste0(ukraine_folder, save_fname_ukr_mod_df)) usethis::ui_done(glue::glue("Updated {save_fname_ukr_mod_df} through {max(ukr_mod_df$date, na.rm = TRUE)}."))# save the maximum date to the file latest_date.text to be used by the lua scriptwrite(as.character(max(ukr_mod_df$date, na.rm =TRUE)), "latest_date.txt")return(ukr_mod_df)}# test page on a single date# test_ukrainian_page(in_ukraine_urls[3])test_ukrainian_page <-function(known_url, adate =NULL) {# use to check in_ukraine_urlsif (!is.character(known_url)) return()if (is.null(adate)) { link <- known_url adate <-str_extract(known_url, pattern ="(\\d{4})/(\\d{2})/(\\d{2})") |>ymd() x <-read_lines(link) } else { x <-fetch_ukr_mod_text(adate, known_url = known_url) }# if all else fails, try Ukranian# "https://www.mil.gov.ua/news/2023/09/21/ukrainski-zahisniki-za-dobu-likviduvali-490-okupantiv-znishhili-41-artsistemu-i-15-bbm-voroga-genshtab-zsu/" the_line <- x[str_detect(x, key_phrase)]if (the_line ==0) stop(paste0("In test_ukrainian_page, key line not found. ", key_phrase))if (length(the_line) >1) stop(the_line[1:5])# print(the_line)# Now extract the number extracted_personnel <-extract_number(the_line, pattern_ukrainian_personnel)# The extracted_number will include the prefix phrase,# so we'll need to use str_replace_all to remove it and extract only the number# extracted_number <- str_replace_all(extracted_number, "[^\\d]", "") ukrainian_page_additions <-tibble(report = the_line, adate) ukrainian_additions <-parse_ukr_mod_ukraine(ukrainian_page_additions)}# xx <- map(in_ukraine_urls, test_ukrainian_page, .progress = TRUE) |> list_rbind()
Weekly Russian Losses According to Ukraine Ministry of Defense
This is only the Ukraine side of the story.
The report always refers to “liquidated personnel,” but there’s some ambiguity about what that means.
The Ukrainians use the word “liquidated” to refer to the Russian losses. However, that word choice leaves the actual figure of killed and wounded up to interpretation. With “liquidated” Kyiv could mean “killed” or “killed and wounded.” – Stavros Atlamazoglou at the website 19fortyfive.com
Presumably the personnel losses are an estimate. There are lots of factors that could affect how close these counts come to reality. Western intelligence sources sometimes report their own estimates of Russian losses. Those do not necessarily match these counts. The plot may help to assess the change in the tempo of the war over time.
The vertical red lines on the plot intended to help relate the time line to some of the reported events during the war. Each line is identified by a letter. The labels on the plot are necessarily terse; the table below lists them with a bit fuller labels.